GPT在NLU領域經過finetuning之後很難擊敗Bert的表現,主要是因為現在預訓練模型的方法有很多種(主要是MLM),但是在finetune的時候,常常和預訓練不一致,因此作者發明了P-tuning的方式讓預訓練和finetune的任務一致,最後實驗結果GPT利用P-tuning可以贏過和同等參數量的Bert做finetune的效果,
手刻Prompt的缺點:

手刻的prompt,根據不同形式的prompt finetune出來的效果會有很大的差異,上圖可以看到[Y]的位置,還有問法都會導致效果會有很大的差別,比如說第三句和第四句,只是[Y]前面多加一個In後,模型的效果就有很大的提升,相差20%左右,製造一個好的prompt有點要碰運氣,加上一些經驗才有辦法讓模型表現好,因此作者希望用自動化的方式建立prompt,排除掉人為的因素.
P-tuning方法
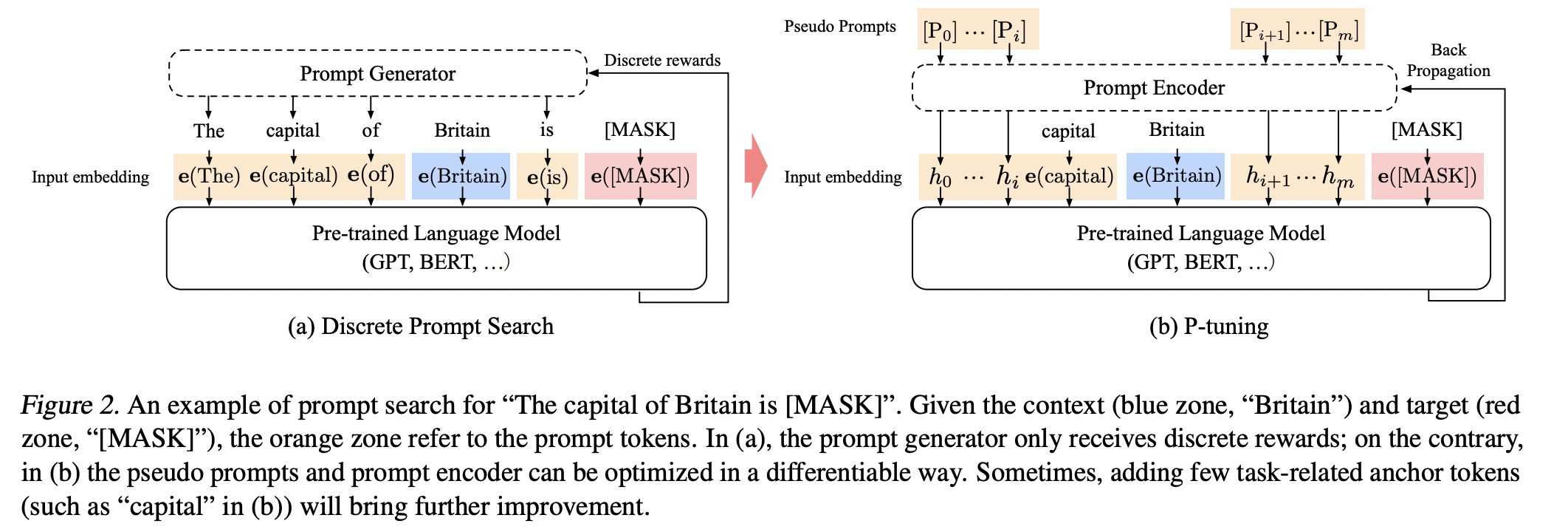 Prompt其實就是將finetune的任務轉換成
Prompt其實就是將finetune的任務轉換成填空的任務,來更貼近預訓練的MLM任務,左圖一般的Prompt方法都是discrete,橘色的區域是人工製造的prompt token,藍色則是context,紅色是要預測的目標,
橘色區域通常是有模板去產生出來的,然後放進預訓練模型finetune,效果很取決於這個模板好不好,適不適合這個任務。
因此作者就想要解決這個問題,排除掉人為的因素,因此作者提出右圖的方法,他把原本橘色區域的prompt token原本由模板產生,改成用embedding的形式,那這embedding怎麼來的,其實就是直接創新的詞[PROMPT1]-[PROMT10],然後輸入一個神經網路,至於這個神經網路怎麼設計後面會講,這些詞原本的預訓練模型也沒有看過,也不在乎他是不是自然語言,原因很簡單,因為我們希望的是我們利用這些模板可以學到要怎麼樣去完成downstream task,而這些模板就是經過參數優化後,找到的一群參數,至於他本身是什麼樣的字或符號其實並不用太在意,背後所學到的參數才是最重要的。
那不同於finetune方法的差異在哪裡呢?P-tuning會讓預訓練模型的參數固定,只學習橘色區域的prompt token,這樣做的原因可以讓模型利用之前從大量文本中學到的知識,來達到更好的效果,然而finetune因為是調整整個模型的參數,而且常常預訓練任務和下游任務常常是不一樣的,很容易導致災難性遺忘,打亂原本學習到的參數。
P-tuning方法改進
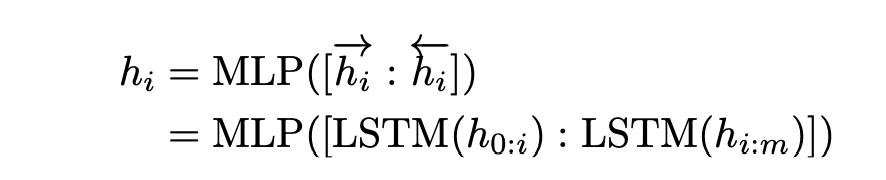 但當我們不在乎prompt template是由字還是符號組成的時候,我們只是把他們當成可學習的參數,希望利用這個template更貼近預訓練模型時的目標任務,但有兩個問題,我們如果不在乎是用什麼符號去建立template,
但當我們不在乎prompt template是由字還是符號組成的時候,我們只是把他們當成可學習的參數,希望利用這個template更貼近預訓練模型時的目標任務,但有兩個問題,我們如果不在乎是用什麼符號去建立template,第一個問題會是這些符號的embedding會先隨機初始化,然後用SGD做梯度下降,會使得這些參數只在很小的區域做更動,很容易就落到局部最小值,第二個是這些符號都是不相關的,但文字是有相關性的,因此為了解決上述兩個問題,作者使用了雙向的LSTM加上Relu再加上兩層的MLP,來解決這個問題,在inference的時候,LSTM會被拿掉,直接使用prompt tuning好的模型inference,數學公式如下:
資料集
這篇論文使用了兩個評估方法來對P-tuning的方法做測試,分別是LAMA和SuperGlue,LAMA主要是利用知識圖譜搭配填空法來對預訓練的模型做測試,舉例來說,從知識圖譜中抽取一個三元組(Dante, born-in, Florence),然後將它轉換成prompt “Dante was born in [MASK]”,然後叫預訓練模型去預測那個[MASK],如此一來可以檢測預訓練模型有從預訓練的參數中提取到多少的知識.
Knowledge Probing(測試模型學到多少知識)

然後可以看到上圖是將各種預訓練模型用在LAMA資料集上,看說哪個預訓練模型可以得到最多的知識,因為要知道預訓練模型知道多少知識,所以模型的參數都是固定的,動的只有要prompt tuning的那些參數~~~這張圖表有以下幾個值得注意的點:
- 左表顯示分別在原始的預訓練模型、Discrete Prompt以及P-tuning上,可以看到相較於原始的bert,P-tuning的效果比bert高了19.5%,相當驚人的高,從這個數字也可以顯示,bert其實並沒有把預訓練的知識利用完全,再來是和過去Discrete Prompt的方法比,也提升了7.3%,
從這邊就可以知道P-tuning是可以有效的從預訓練模型中萃取出知識.Prompt也相較於finetune能夠提取更多的模型知識. - 右邊這張表則是要用GPT和bert去比較,因為GPT和Bert的字典不一樣,所以作者才使用另一個資料集LAMA-29k,作為評測標準,第一個欄位是是模型,第二個欄位是MP(Manual Prompt)人工生成的prompt,第三欄FT則是finetune,第四欄則是MP+FT,人工生成的Prompt+加上finetune,第五欄則是P-tuning則是本篇的方法,這個數據有幾個值得的點可以觀察:
- 在MP人工生成Prompt的時候,GPT的表現遠輸於Bert,有可能是人工生成的prompt並沒有找到一個好的prompt,而且Bert在人工生成prompt上面表現也輸finetune,
由此可知人工生成的prompt並沒有比較好. - 除此之外Bert在finetune和人工生成的prompt+fintune上也贏過GPT
- 不過finetune有一個壞處是在
需要大量資源的預訓練模型(MegatronLM)是沒辦法finetune的,而prompt確可以. - 最後則是P-tuning的部分,可以看到P-tuning除了成效好過其他方法之外,GPT的成效也超越了Bert,而且Bert本身P-tuning的結果也略勝finetune.
小結論:
理論上來說finetune應該要比p-tuning表現還要好才對,因為finetune有更多參數可以學習,p-tuning則比較少,但因為knowledge-probiing的知識都是寫死的,這些模型都沒有inference過,因此finetune很容易造成災難性的遺忘,而P-tuning因為預訓練模型的參數沒動,所以可以使用這些知識找到好的prompt
NLU task 在不同方法上和不同參數量上的比較
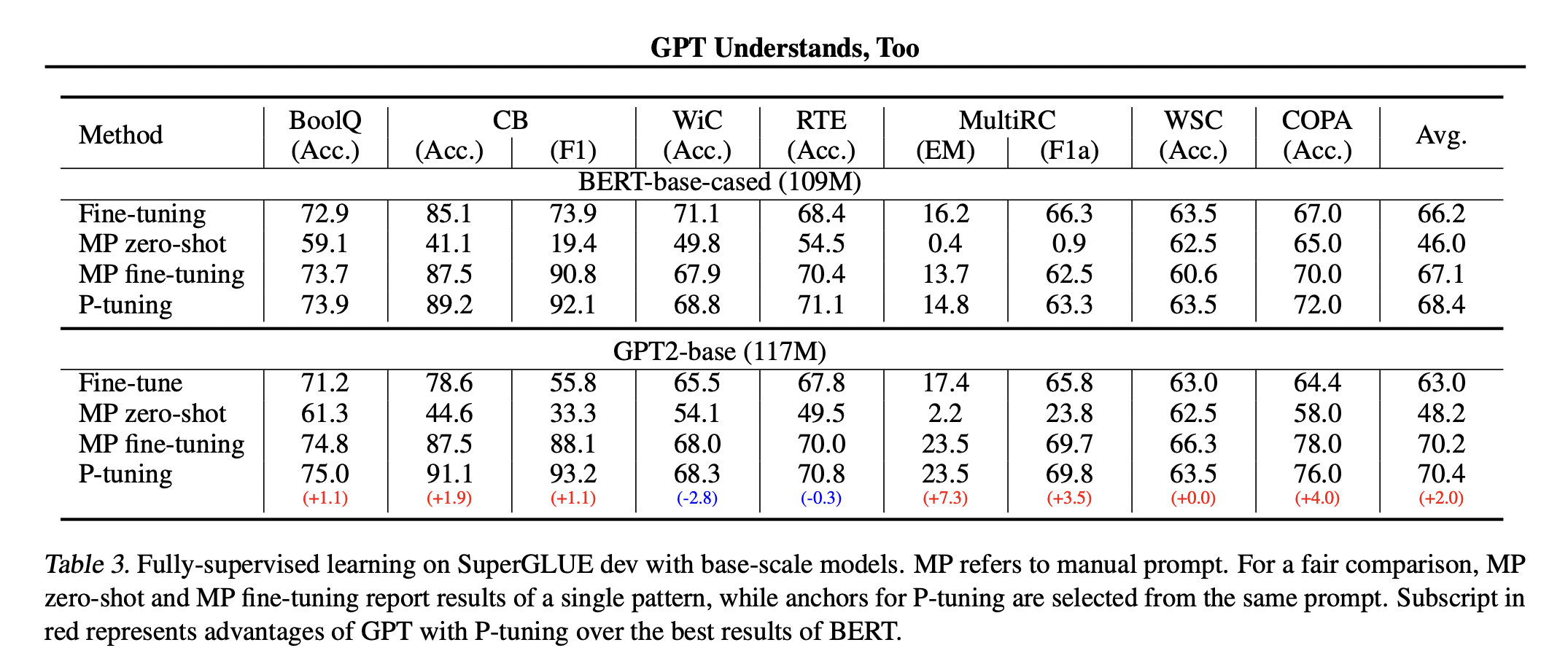
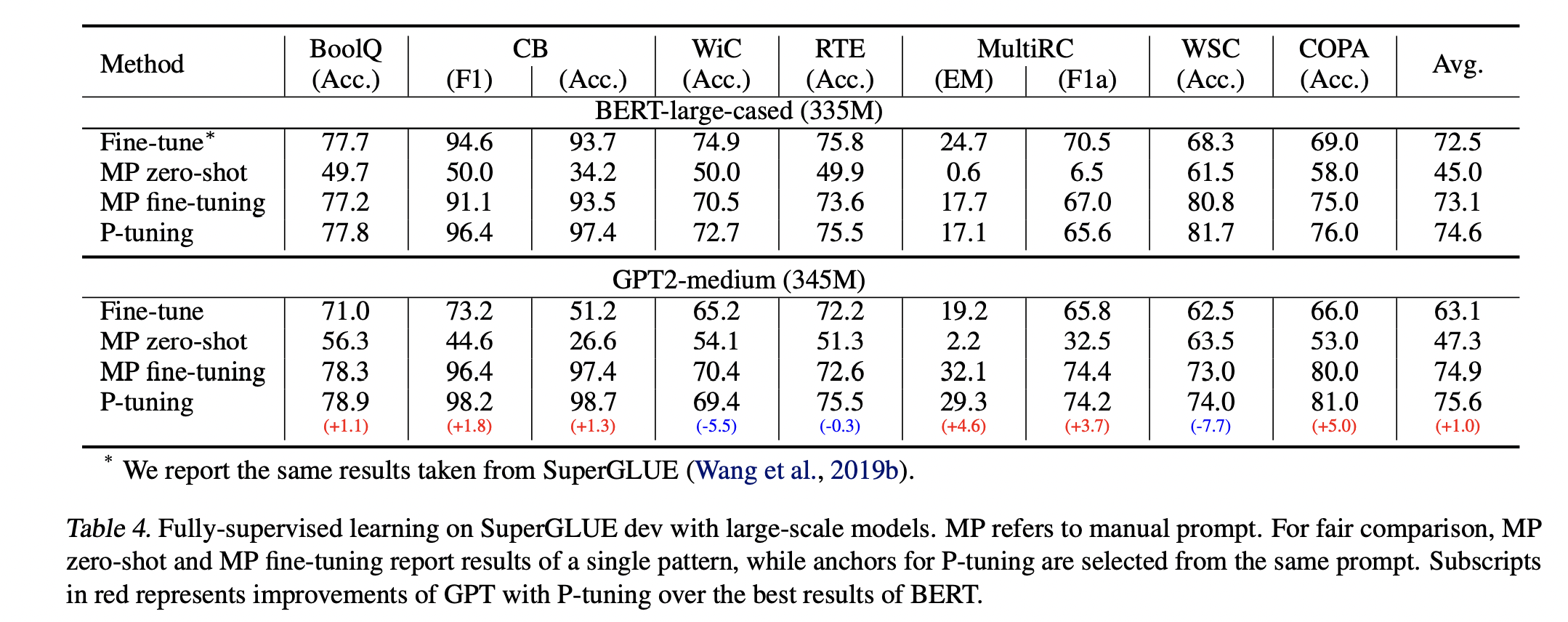 下面兩張圖主要就是比較finetune、人工prompt zero shot、人工prompt finetune以及P-tuning分別在不同參數量下的表現,可以看到P-tuning除了在Wic和MultiRC表現比較差以外,其他資料集都表現的很好,原因有可能是因爲Wic和MultiRC這兩個資料集比較大,所以才讓finetune佔優勢,也可以顯示P-tuning在低資源的情況下,可以取的相對好的表現
下面兩張圖主要就是比較finetune、人工prompt zero shot、人工prompt finetune以及P-tuning分別在不同參數量下的表現,可以看到P-tuning除了在Wic和MultiRC表現比較差以外,其他資料集都表現的很好,原因有可能是因爲Wic和MultiRC這兩個資料集比較大,所以才讓finetune佔優勢,也可以顯示P-tuning在低資源的情況下,可以取的相對好的表現
few-shoting learing & GPT3 輸了
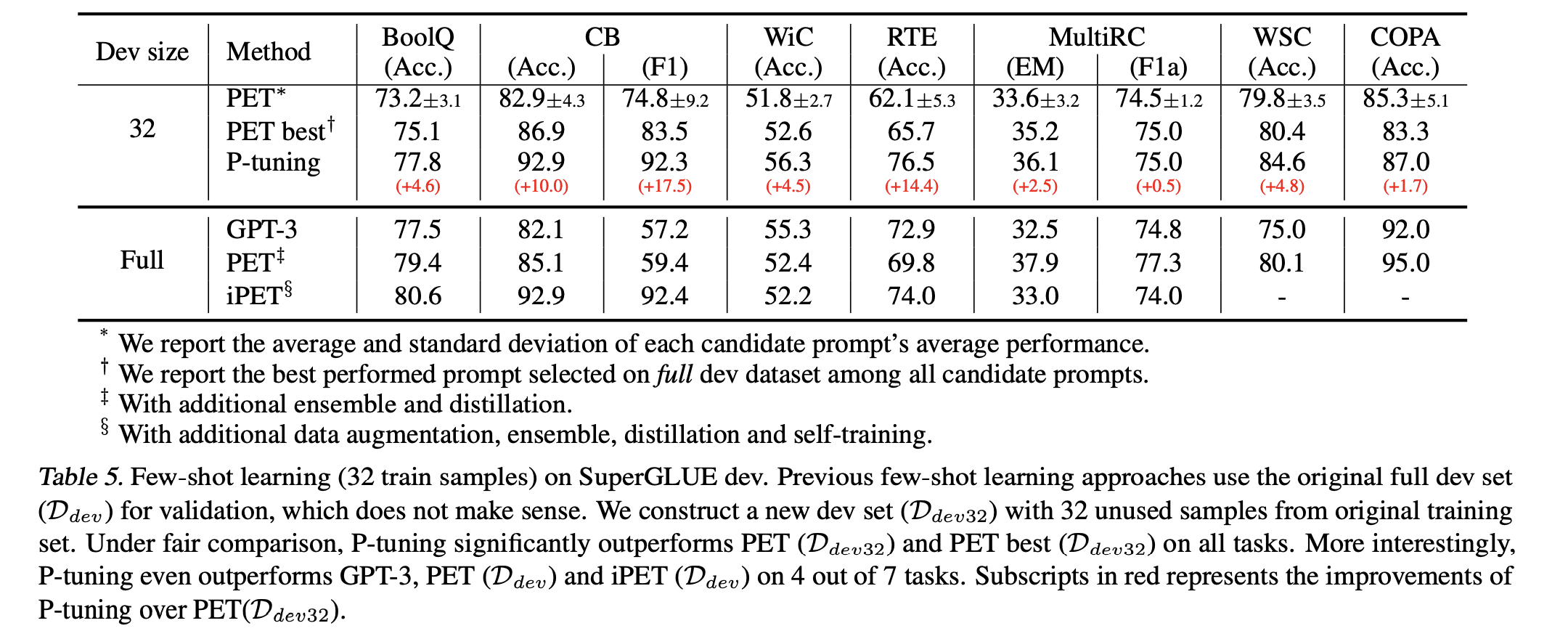
 下圖則是不同few shot learning的方法,在驗證集只有32筆和全部的情況下,過去few-shot learninig常常在巨大的驗證集上調參然後挑選最好的model,這也是不切合實際的!真正的小樣本學習,訓練集驗證集都要小!不然就很容易overfitting測試資料集,然後可以看到P-tuning不僅僅超越過去few shot的方法,
下圖則是不同few shot learning的方法,在驗證集只有32筆和全部的情況下,過去few-shot learninig常常在巨大的驗證集上調參然後挑選最好的model,這也是不切合實際的!真正的小樣本學習,訓練集驗證集都要小!不然就很容易overfitting測試資料集,然後可以看到P-tuning不僅僅超越過去few shot的方法,除此之外甚至連GPT3都被P-tuning打敗,令人震驚!!!這篇文章給我們帶來了全新的思路,不一定要用很多的finetune資料然後還有很多參數才能達到很好的效果,簡單利用幾個樣本加上少少的參數一樣可以在預訓練模型上做得好
結論
作者證明了GPT在NLU領域是被低估的,之前只是沒找到一個好的方式應用在nlu領域~~~
這一篇的貢獻
- P-tuning 給了我們在有限算力下調用大型訓練模型的思路
- 人工構建模板,很吃專家知識,模型的效果很難控制,不同模型有可能有不同的結果
- P-tuning放棄了
“模板由自然語言構成”的假設,把它變成梯度下降求解連續參數優化的問題(找到一組模型參數讓模型表現更好),模板的關鍵在於怎麼用,不在於用什麼東西組成 - 使得finetune的時候的任務和預訓練更加一致
參考資料:
 AWS lambda 介紹與fastapi部署教學
AWS lambda 介紹與fastapi部署教學