
最近在研究Task Oriented Chatbot方面的東西,看到微軟的這篇論文結合人工規則以及神經網路覺得很有趣,所以想要來分享大家~~~
Hybrid Code Network 聽名字就知道他是一種混合的神經網路,混合了人工規則以及神經網路,所以叫Hybrid Code Netowrk,簡稱HCN。
論文特色
- 大部份的方法都要用大量的對話去訓練模型,HCN可以用很少的數據就訓練出很好的效果。
- HCN 可以分別使用監督式學習以及強化學習來做訓練
資料集介紹
跟其他的介紹文不同,我想先從資料集開始說明,這樣對這領域比較陌生的讀者也能快速地知道模型的輸入是什麼以及整個模型的運作流程。
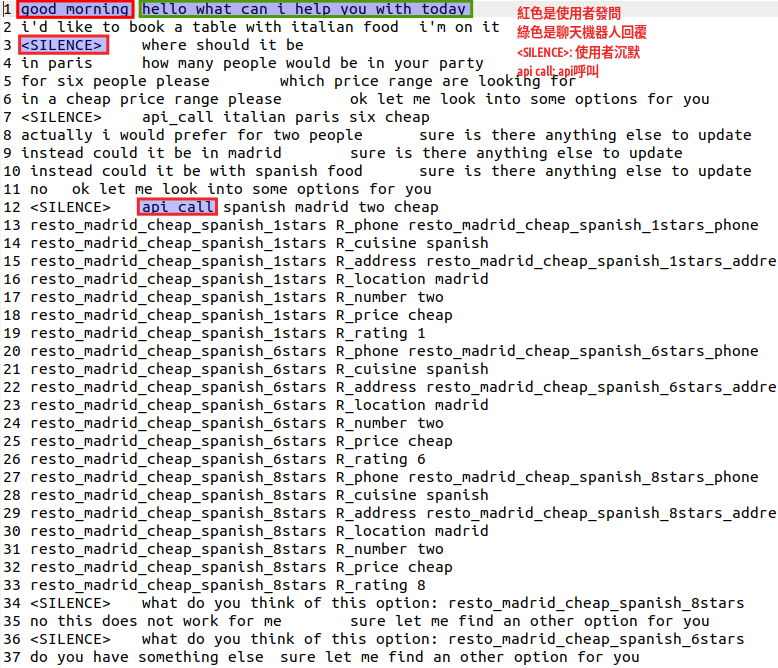
首先可以看到下圖是一個多輪對話集會長的樣子,資料集是bAbI dialog Task5,這個對話集主要是用來餐廳訂位,紅色框框代表使用者的發問,綠色則是聊天機器人的回復,所以會是一問一答的形式,然後透過和使用者的對話去得到我們想要得到的資訊,這個對話集還會帶有一些特殊符號來表示使用者或者是聊天機器人的狀態,比如說<SLIENCE>代表使用者沉默,api call代表聊天機器人透過API去查詢使用者想要的資訊。
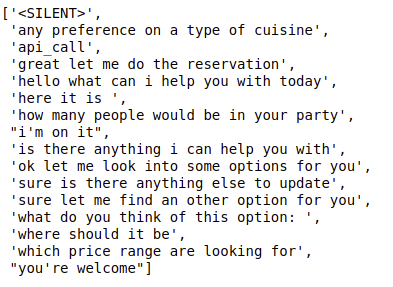
下面這張圖則是列出所有聊天機器人會回答的語句,是制式化的回答,固定就這麼幾句,然後我們要讓模型去預測要用哪一種回復。
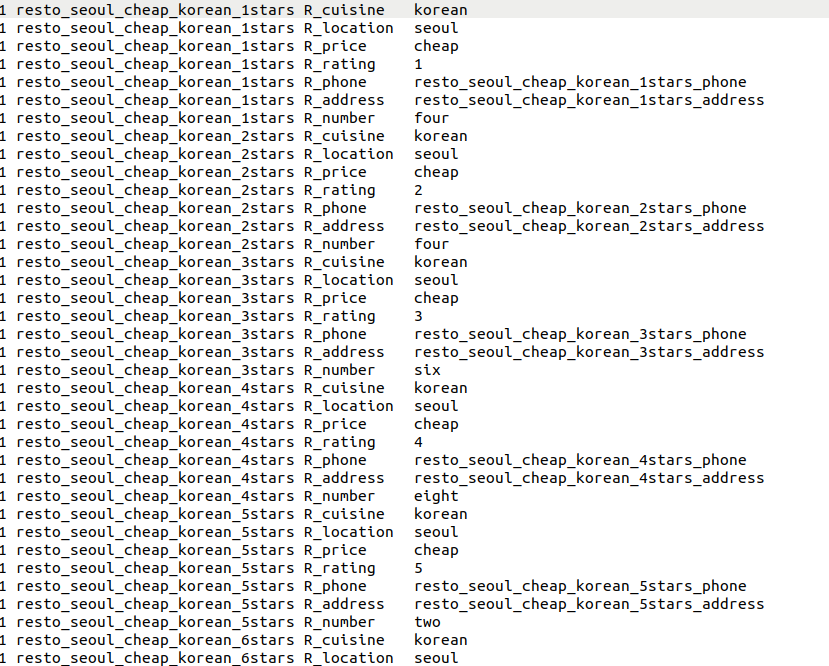
而下面這張則是聊天機器人使用api call的時候,根據使用者提供的資訊去資料庫中搜尋相關的餐廳資訊,比如說他的價錢、菜色以及地點等等
那介紹完資料集以後我們就開始介紹模型吧!!!
模型架構
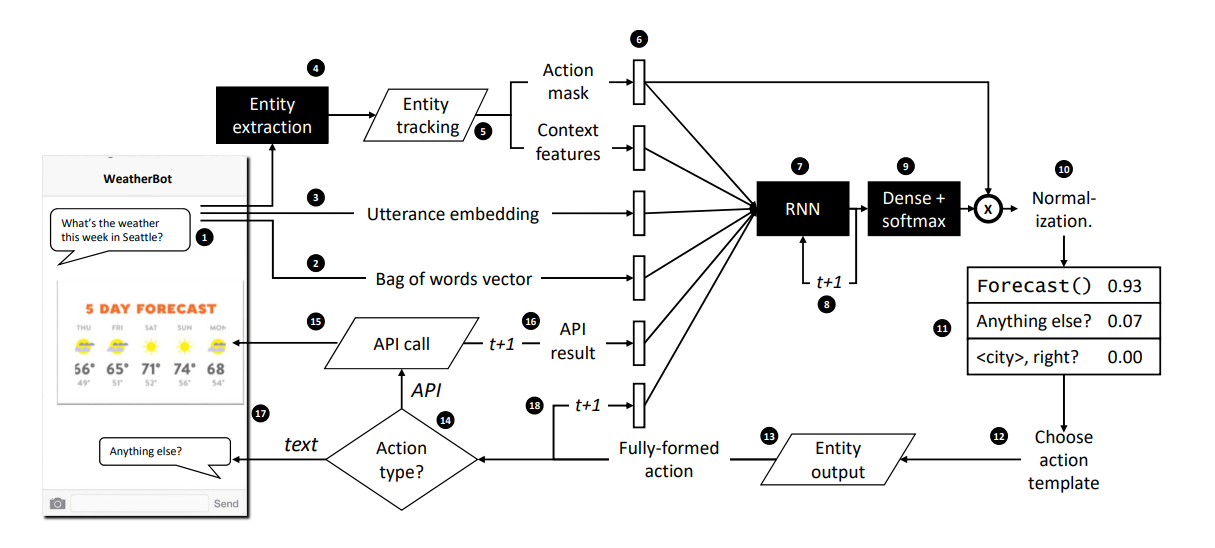
第一步:
使用者發出問題詢問聊天機器人
第二~五步:
將使用者的問句分別轉化成以下四種向量
- 詞袋向量
- Utterance Embedding(利用預訓練的詞向量轉化)
- Context features
- Action Mask
其中要特別講的的是第三個和第四個向量,也是這個模型最特別的地方,首先先來講Context features,
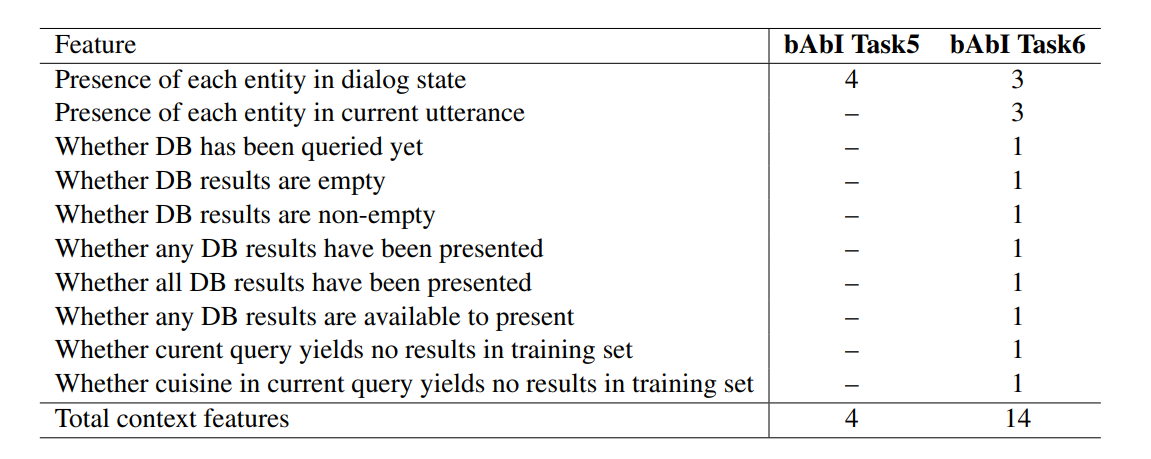
Context feature是什麼呢???其實就是紀錄一些使用者對話的狀態或者是聊天機器人做過的動作,比如說下圖,使用者問說I'd like to book a table with italian food,我們就用一個四維的向量紀錄這句話代表的是哪一種Entity的類型,像這句是在問菜色,因此在cuisine那一欄紀錄1,來表示當前的狀態。

下圖這是其他在這個模型使用的context feature,來表達當前的狀態。
再來講Action Mask,這裡就是人工制定規則的地方,可以根據對資料集的領域知識決定要使用哪種回復,也可以根據context feature去決定,可以看到下圖也是一個向量,維度是上面資料集提到的16種聊天機器人可能給出的回覆,用這個來控制在不同的情況下,讓機器人傾向回復標註為1的地方,0就是希望不要回復這個,這邊就是要自己去編寫規則,讓模型知道某些情況應該回復什麼。
第七~十一步:
把第二~六步得到的向量Concat起來,放進RNN裡去,最後做softmax乘上action mask,用規則過濾掉一些不可能的回答後,做正規化後得到最後Action的機率分布,取最大值當作聊天機器人的回復。
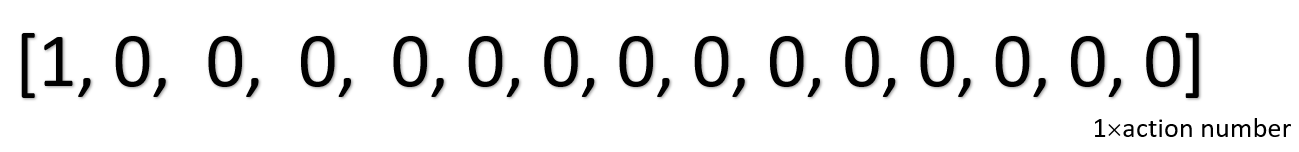
第十二~十八步:
因為有些動作會需要填值在回覆給使用者,比如說: What do you think of this option:,因此我們會將前面得到的entity填到動作需要填空的位置才回覆給使用者,也有可能預測出來是要api call,我們就會去查詢相關的餐廳資料再一一詢問使用者,並且也會把這些結果當作特徵當作下一個時間點的模型輸入,以上就是整個模型的訓練,是採監督式的學習,訓練的時候batch_size會是1,一句一句的餵進去訓練,另外也可使用強化式學習去學習和使用者之間的互動。
實驗結果
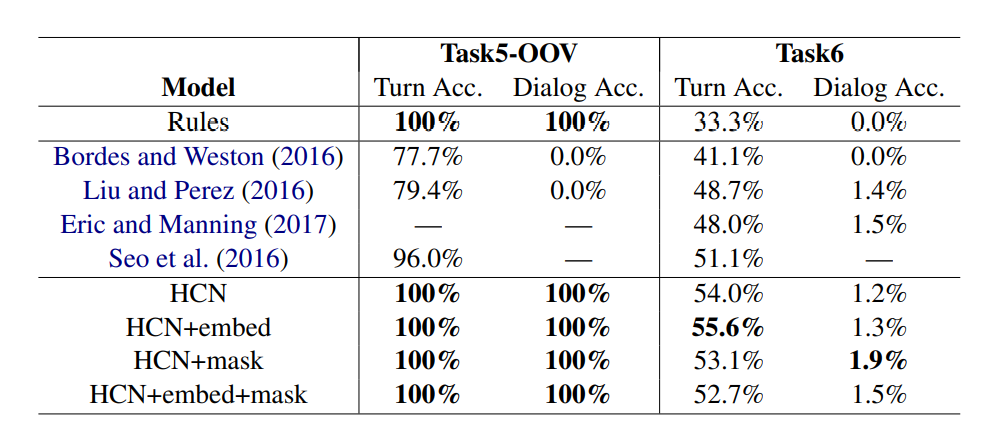
HCN實驗分別實驗在Task5和Task6上,Task5是使用babI資料集,他的測試集會有一些訓練集不存在的Enitity(Task 5 OOV),Task6則是DSTC2的資料集,這個資料集相對Task5來說比較難,因為Task5是用規則去生成的,而Task6則是真實對話,機器人要回答的模板也比較多共有56種,Task5則有16種。
評估指標
- Turn Accuracy: 一輪中每一次對話的準確度
- Dialogue Accuracy: 一整輪對話的準確度
- 新的評估指標(如下圖): 評估對話誰可以持續比較久
C(HCN-win)代表HCN在多輪對話中比rule還要晚預測錯誤,C(rule-win)代表rule在多輪對話中比HCN晚錯,這個指標如果越大,代表HCN的效果越好,對話可以持續得越久。
\[\frac{C(HCN-win)-C(rule-win)}{C(all)}\]可以看到HCN在Task5的表現可以跟Rule一樣好,但在Task6的時候Rule表現得不好,HCN可以勝過Rule以及其他的Baseline,還是有一些進步,但這個效果的提升很吃在規則的編寫,作者也沒公布源碼,所以也沒辦法實際感受一下XD
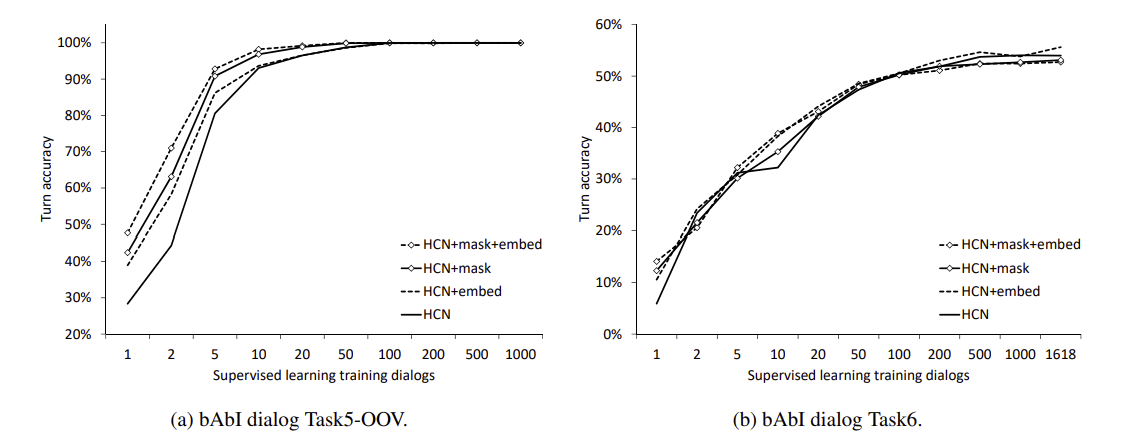
而下面兩張圖則可以看出HCN只要很少量的數據就可以訓練得很好。
結論
來做個結論吧,這篇HCN結合了規則以及神經網路,雖然可以用很少的訓練資料就訓練到很好的效果,但是對資料集所需的領域知識卻要求很高,在Task5的時候因為都是規則生成的對話集所以很容易達到很好的效果,但在Task6就比較難用Rule去達到很好的效果,這也是這個模型的缺點,用了更多人工來減少對訓練資料的依賴,就看使用者要怎麼取捨了~~~
有什麼問題可以留言在下方跟我說,喜歡我的文章在幫我拍拍手喔~~~~
